“E’ più importante conoscere che tipo di persona ha una malattia, piuttosto che conoscere il tipo di malattia che ha la persona” sosteneva Ippocrate oltre duemila anni fa, fondando, con la sua teoria dei quattro umori per la diagnosi e la prescrizione della terapia per pazienti individuali, la medicina personalizzata.
Non ci sono mai stati, come oggi, tanti credenti non praticanti della medicina personalizzata, recentemente chiamata anche medicina di precisione. Infatti, nonostante nel 2014 siano stati contati oltre 100 farmaci con associati biomarker e informazioni farmacogenetiche, il 40% dei quali in oncologia, ed innumerevoli esempi di variabilità della risposta alla terapia tra pazienti, l’attuale medicina è ancora largamente basata sul modello “one-size-fits-all”, dove pazienti per i quali è stata diagnosticata la stessa patologia vengono trattati con gli stessi medicamenti e le stesse dosi [1, 2]. Sebbene questo modello in molti casi abbia riscosso successo, per alcuni trattamenti lo stesso approccio può portare ad evitabili reazioni avverse ai farmaci, ridotta efficacia, mancata ottemperanza per intolleranza da parte del paziente e aumento dei costi dell’assistenza sanitaria [3].
Se “per fare un albero ci vuole un fiore”, come cantava Sergio Endrigo, per fare la medicina personalizzata ci vuole la farmacogenetica, che interroga le varianti nella sequenza del genoma implicate nella variabilità interindividuale della risposta al farmaco.
Nonostante gli inarrestabili progressi della tecnologia nelle analisi genetiche ed il continuo incremento di informazioni che associano pattern genetici a malattie e rispettivi trattamenti, l’implementazione della farmacogenetica nella pratica clinica incontra ancora vari ostacoli: disponibilità di piattaforme per genotipizzazione rapida e di test in grado di fornire risultati attendibili, accurati in modo costante; assente standardizzazione del referto; mancanza di trial clinici farmacogenetici randomizzati e prospettici volti a validare gli algoritmi che dovrebbero guidare i trattamenti; deficit di molti operatori sanitari nell’interpretazione e nell’utilizzo delle informazioni farmacogenetiche; scarsità di raccomandazioni chiare e linee-guida curate e revisionate da parte di società scientifiche ed enti di vigilanza che traducano i risultati dei test di laboratorio in decisioni sulla prescrizione per specifiche coppie farmaco-gene; carenza di tecnologie dell’informazione in grado di fornire supporto nelle decisioni in medicina genomica come la cartella clinica elettronica; implicazioni etiche e legali per la gestione e la refertazione dei dati genetici; costi e rimborsi [3, 4].
Se le questioni etiche non hanno ragione di esistere, o comunque dovrebbero essere facilmente risolvibili, in quanto la maggior parte delle varianti farmacogenetiche non è considerata un fattore di rischio di malattia, nella stima dei costi occorre tenere in considerazione le onerose inefficienze che l’introduzione della medicina personalizzata nel sistema dell’assistenza sanitaria permetterebbe di risolvere, come la prescrizione con approccio per tentativi ed errori ed il trattamento, con o senza ospedalizzazione, delle reazioni avverse ai farmaci [1, 4].
Per superare molte delle altre difficoltà nella medicina oncologica, la Diatech Pharmacogenetics fornisce il sistema Myriapod® ADMET (cod. SQ040), che permette il rilevamento e l’identificazione di 126 polimorfismi in 58 geni coinvolti nell’Assorbimento, nella Distribuzione, nel Metabolismo, nell’Eliminazione e nella Tossicità dei chemioterapici antitumorali, mediante Spettrometria di Massa MALDI-TOF associata alla tecnologia Single Base Extension.
La selezione dei polimorfismi analizzabili con Myriapod® ADMET è stata basata sulle linee-guida e raccomandazioni del Clinical Pharmacogenetics Implementation Consortium (CPIC), la principale organizzazione che si occupa di dare indicazioni sulle opzioni terapeutiche in base ai risultati dei test farmacogenetici [3]. Le linee-guida contengono tutte le informazioni sulle varianti funzionali dei geni clinicamente rilevanti e sui probabili relativi fenotipi, mentre le raccomandazioni riguardano la scelta ed il dosaggio del farmaco in base al fenotipo. Le linee-guida del CPIC sono revisionate accuratamente, costantemente aggiornate e non legate ad alcun prodotto o servizio commerciale, piattaforma di genotipizzazione o interesse finanziario e, insieme alle raccomandazioni, sono disponibili gratuitamente sul sito PharmGKB (http://www.pharmgkb.org/index.jsp) [4].
La piattaforma Sequenom, su cui Myriapod® ADMET è stato sviluppato, grazie alla sua elevata capacità multiplexing, permette di arrivare al genotipo di 3840 o 15360 polimorfismi per seduta analitica (su piastra da 96 o 384 pozzetti rispettivamente) in meno di 10 ore a partire dal DNA e con un’accuratezza maggiore del 99.7%, quindi con tempi e costi di gran lunga inferiori e throughput superiore rispetto a quelli del sequenziamento di nuova generazione, considerato troppo spesso e a sproposito come il cavallo di Troia per l’ingresso della medicina personalizzata nella pratica clinica.
Inoltre, la validazione di Myriapod® ADMET per uso diagnostico in vitro, garantisce l’ottenimento di risultati attendibili in maniera costante e standardizzata, anche grazie al software per l’analisi dei dati co-sviluppato con la società BiMind, che può essere gestito come uno dei moduli della cartella clinica oncologica informatizzata creata dalla stessa azienda partner di Diatech Pharmacogenetics e contenente anche informazioni farmacogenetiche.
L’attuale paradigma della medicina personalizzata prevede l’utilizzo dei dati genetici individuali in congiunzione con altre variabili cliniche, familiari e demografiche allo scopo di assistere il paziente con un approccio olistico e raffinare prevenzione, diagnosi, terapia e prognosi [3]. Con questa ottica, Myriapod® ADMET a breve entrerà a far parte di un progetto europeo per lo sviluppo di un modello in silico di tumore, costruito su misura del paziente. Questa sorta di avatar del paziente oncologico verrà modellato tenendo in considerazione i dati personali e clinici, quelli forniti dalla farmacogenetica e, laddove disponibili, dalla proteomica e metabolomica ed avrà la missione di supportare l’oncologo nella scelta del trattamento che ha la maggiore probabilità di ottenere un miglioramento della risposta e/o della sopravvivenza. I trial clinici prospettici previsti in questo progetto internazionale consentiranno anche di definire la validità e l’utilità clinica dei biomarker oggetto di analisi di Myriapod® ADMET e di validare gli algoritmi destinati a guidare i trattamenti personalizzati.
Infine, in attesa che le istituzioni preposte all’educazione preparino la nuova generazione di medici, farmacologi, laboratoristi e infermieri e che ogni ospedale adotti un sistema informatico in grado di catturare, aiutare ad interpretare e condividere tutti i dati dei pazienti, inclusi quelli genomici e, insieme, i dati fenotipici e medici e le scoperte della ricerca farmacogenetica, per la piena realizzazione della medicina personalizzata occorre che tutti i professionisti che ruotano intorno al paziente siano abbastanza “hungry” e “foolish”, parafrasando Steve Jobs, ovvero avidi di conoscere le origini di una determinata risposta al farmaco e liberi di pensare in modo non convenzionale e di andare oltre i rigidi e obsoleti protocolli della medicina attuale.
Riferimenti bibliografici
1. The Personalized Medicine Coalition, The Case for Personalized Medicine – 4th Edition, 2014.
2. E Razvi, Personalized Medicine Market Trends, GEN 2014.
3. NS Abul-Husn et al, Pharmgenomics Pers Med. 2014 Aug 13;7:227-40.
4. AR Shuldiner et al, Clin Pharmacol Ther. 2013 Aug;94(2):207-10.
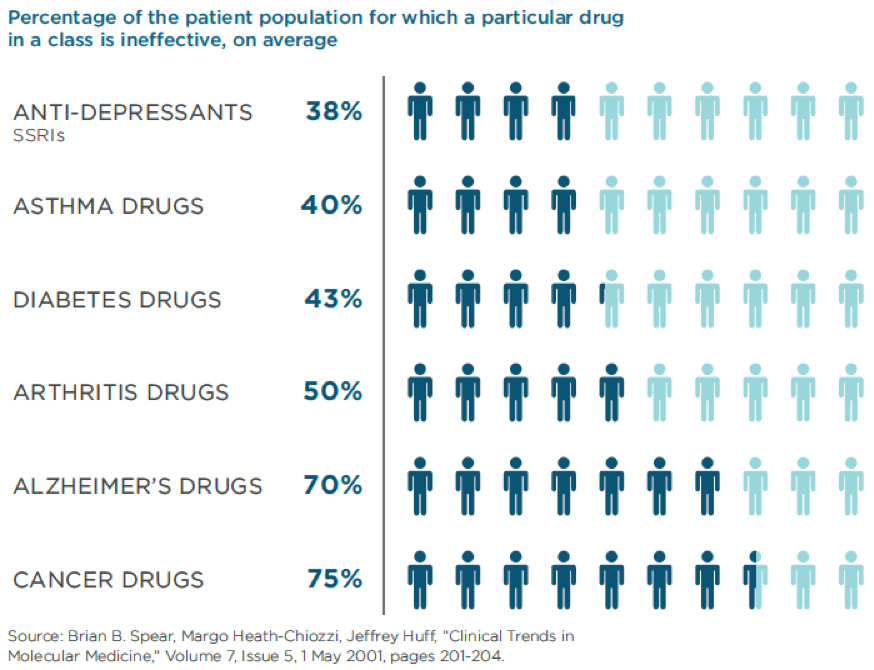
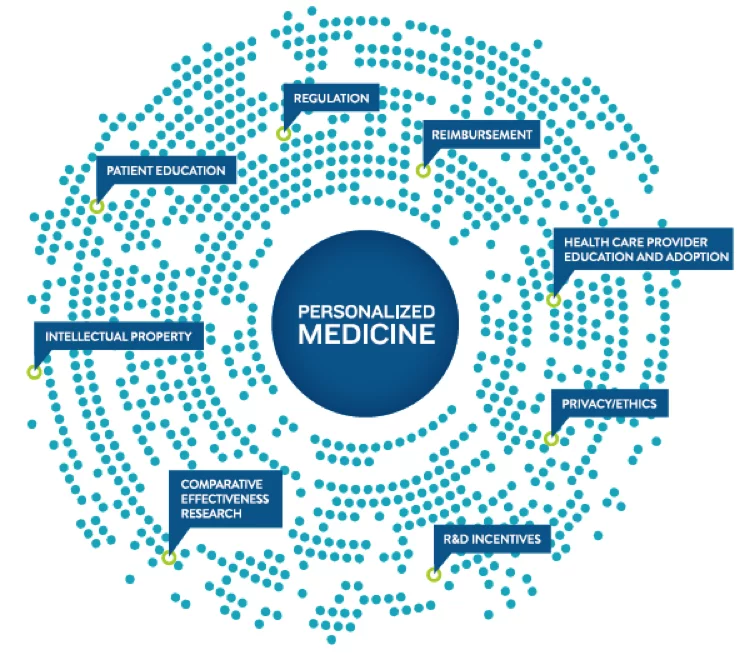

Fonte figure: The Personalized Medicine Coalition, The Case for Personalized Medicine – 4th Edition, 2014.